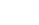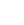武科大網(wǎng)訊 近日,我校計(jì)算機(jī)學(xué)院ONTOWEB研究團(tuán)隊(duì)在AI輔助中華典籍理解方面取得階段性重要成果——在參數(shù)規(guī)模不足傳統(tǒng)大模型十分之一的輕量級架構(gòu)上,仍可顯著超越現(xiàn)有大模型對文言文的理解精度。該成果以“小模型高效理解文言文”為目標(biāo),圍繞古籍?dāng)?shù)字化、傳統(tǒng)文化傳承以及移動端智能應(yīng)用的迫切需求,在語義對齊、語料構(gòu)建與跨模態(tài)表征三個維度形成了完整的方法學(xué)閉環(huán)。相關(guān)論文相繼被ACM TALLIP (2023)、SCI一區(qū)期刊Information Processing & Management (2024)與AI頂會ACL 2025錄用。
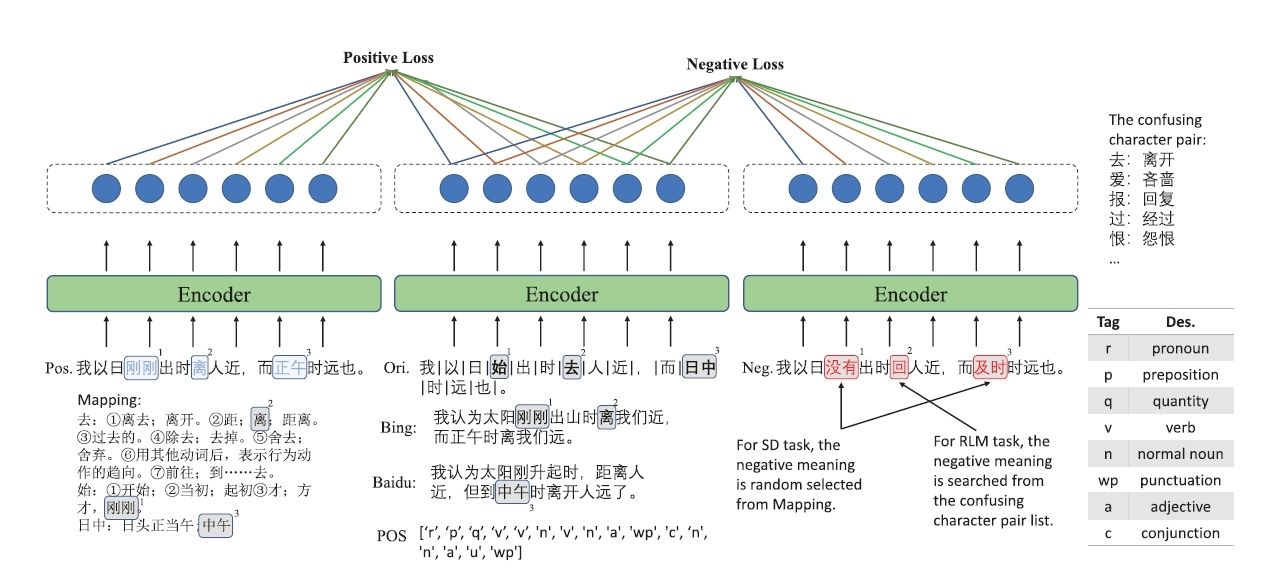
圖1 基于對比學(xué)習(xí)的同義詞判別預(yù)訓(xùn)練任務(wù)
針對文言文本與現(xiàn)代問答之間固有的歷時性語義鴻溝,團(tuán)隊(duì)提出基于對比學(xué)習(xí)的同義詞判別預(yù)訓(xùn)練任務(wù)(圖1),通過字級語義距離度量建立古漢語與現(xiàn)代漢語的精準(zhǔn)映射;在此之上引入增強(qiáng)雙匹配網(wǎng)絡(luò),以選項(xiàng)級注意力推理鏈模擬人類“先比較、后定奪”的閱讀過程,在Haihua、CLT、ATRC等公開數(shù)據(jù)集上取得平均約4%的絕對精度提升,同時將推理時延控制在原有模型的百分之一以內(nèi)。
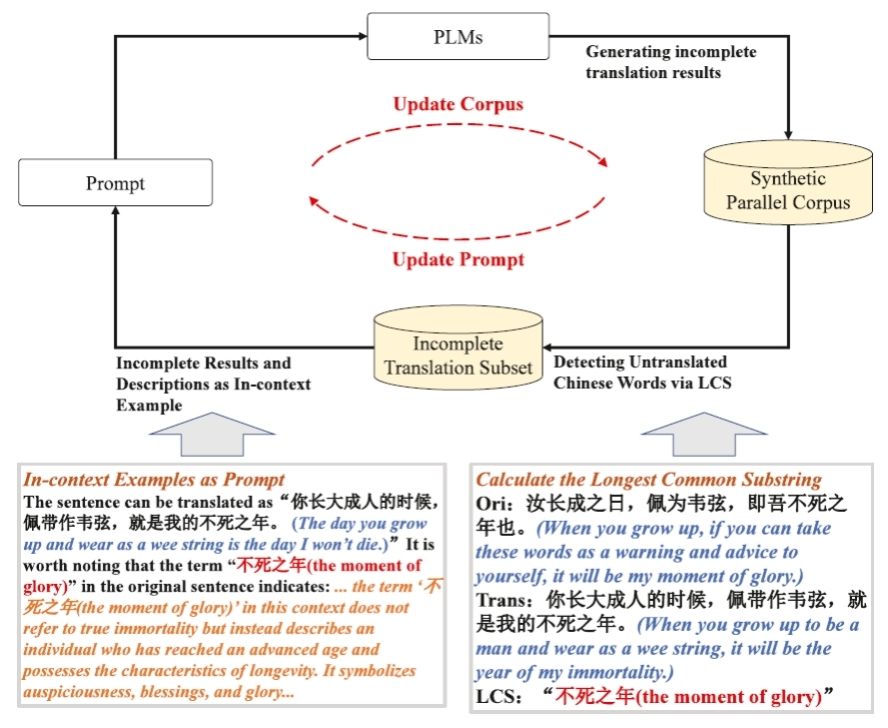
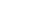
圖2 大語言模型驅(qū)動的漸進(jìn)式譯文精煉框架
為緩解高質(zhì)量平行語料稀缺導(dǎo)致的訓(xùn)練瓶頸,團(tuán)隊(duì)設(shè)計(jì)了一套由大語言模型驅(qū)動的漸進(jìn)式譯文精煉框架(圖2),利用最長公共子串算法自動檢測未翻譯文言詞匯,并通過語義描述示例反復(fù)迭代,最終生成規(guī)模為37.2 GB、未翻譯詞比例降至5.8%的高對齊語料庫,其構(gòu)建成本僅相當(dāng)于傳統(tǒng)人工標(biāo)注的百分之三,卻足以支撐小模型的充分訓(xùn)練。
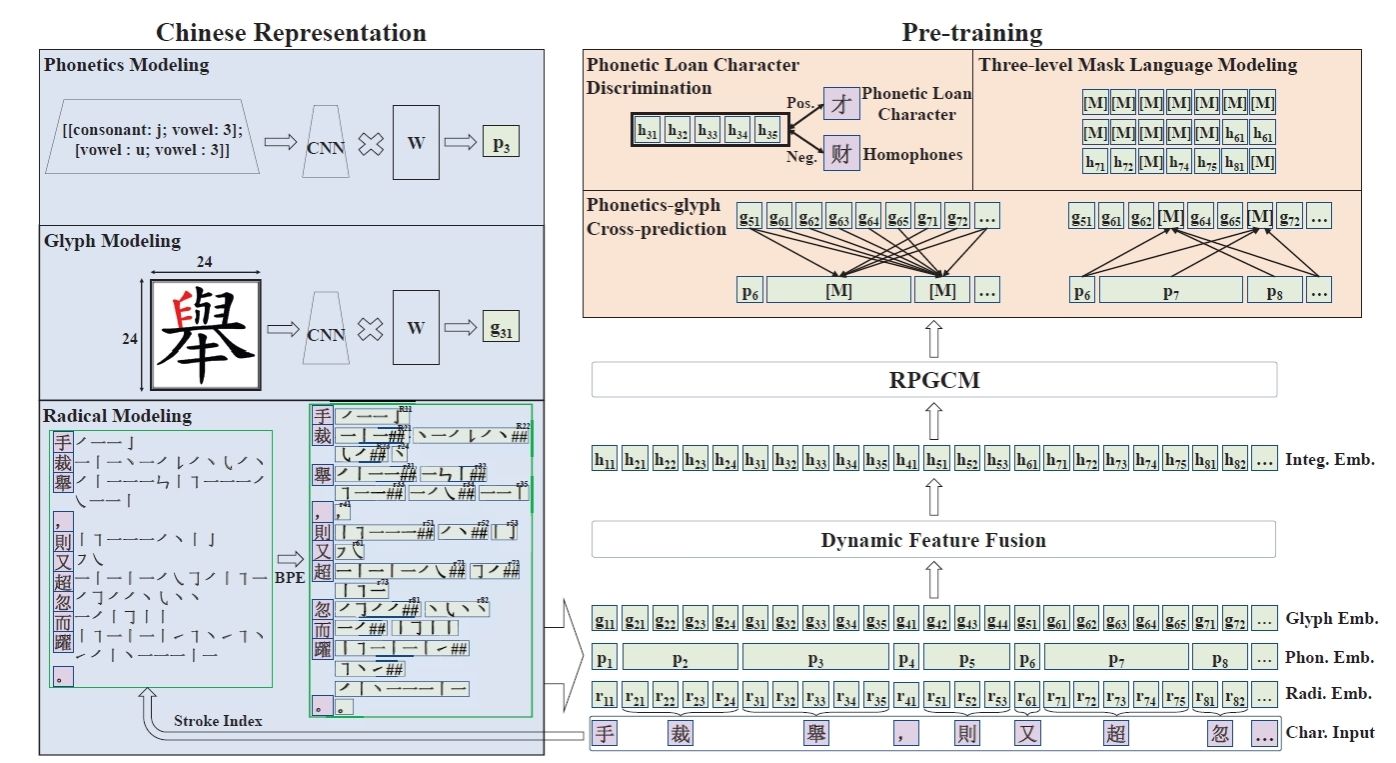
圖3 RPGCN框架示意圖
在漢字自身的形、音、義協(xié)同機(jī)制層面,團(tuán)隊(duì)首次將部首級音形表征引入古典中文預(yù)訓(xùn)練,提出基于筆畫序列BPE子詞切分、部首字形ResNet編碼與多音字拼音CNN編碼的跨模態(tài)融合策略,輔以通假字判別、三級掩碼語言建模與音形互譯三大預(yù)訓(xùn)練任務(wù)(RPGCN),顯著緩解了通假、歧義及低頻字誤讀等問題。在C3Bench、WYWEB等綜合理解基準(zhǔn)的評測中,該輕量級模型均穩(wěn)定反超基線系統(tǒng)3至7個百分點(diǎn),驗(yàn)證了形音義聯(lián)合建模在小參數(shù)條件下的有效性。
同時,參與本項(xiàng)目的博士生們已完成“小模型古文引擎”的SDK封裝,并成功運(yùn)行于主流移動終端,離線支持《史記》《資治通鑒》等典籍的實(shí)時譯文與問答交互。相比傳統(tǒng)BERT模型,單頁古籍拍照上傳后的現(xiàn)代文譯文與關(guān)鍵問答準(zhǔn)確率可達(dá)92%,訓(xùn)練時間降低80%。上述工作為邊遠(yuǎn)地區(qū)學(xué)校、基層博物館及公共文化服務(wù)機(jī)構(gòu)提供了低成本、可擴(kuò)展的智能閱讀解決方案。